UNSUPERVISED LEARNING : CARA KERJA K-means Clustering
ALGORITMA K-Mean Clustering
K-means Clustering adalah salah satu “unsupervised machine learning algorithms” yang paling sederhana dan populer .Tujuan dari algoritma ini adalah untuk menemukan grup dalam data, dengan jumlah grup yang diwakili oleh variabel K. Variabel K sendiri adalah jumlah cluster yang kita inginkan
Bagaimana Proses K-Mean Clustering itu??


Untuk memproses data algoritma K-means Clustering , data dimulai dengan kelompok pertama centroid yang dipilih secara acak, yang digunakan sebagai titik awal untuk setiap cluster, dan kemudian melakukan perhitungan berulang (berulang) untuk mengoptimalkan posisi centroid.
Proses ini berhenti atau telah selesai dalam mengoptimalkan cluster ketika:
>> Centroid telah stabil — tidak ada perubahan dalam nilai-nilai mereka karena pengelompokan telah berhasil.
>> Jumlah iterasi yang ditentukan telah tercapai.
Hasil dari K-Mean Clustering adalah:
- Centroid dari cluster K, yang dapat digunakan untuk memberi label data baru
- Label untuk data pelatihan (setiap titik data ditugaskan ke satu clusters)
Sebagai contoh, Kides akan menunjukkan cara kerja algoritma K-means dengan dataset sampel dari data pengemudi (driver) pada aplikasi Go-Track. Disini Kides hanya akan menggunakan dua fitur driver pada aplikasi Go-Tracks untuk dijadikan variabel : jarak rata-rata per hari dan kecepatan dalam mengemudi per hari . Data ini bersumber dari http://archive.ics.uci.edu/ml/datasets/GPS+Trajectories. Secara umum, algoritma ini dapat digunakan untuk sejumlah variabel , asalkan jumlah sampel data jauh lebih besar dari jumlah variabel. Mari kita lihat langkah-langkah tentang bagaimana algoritma K-means Clustering bekerja menggunakan bahasa pemrograman Python.
Pada kasus ini , Kides akan menggunakan library Scikit-learn dan beberapa data acak untuk mengilustrasikan penjelasan sederhana pengelompokan K-means.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.preprocessing import MinMaxScaler
Seperti yang dapat Anda lihat di atas , Kides mengiport libraries:
>> Panda untuk membaca dan menulis spreadsheet
>> Numpy untuk melakukan perhitungan yang efisien
>>Matplotlib untuk visualisasi data
--- Membaca Data ---driver = pd.read_csv("go_track_tracks.csv")driver.head()

Dari data yang saya miliki terdapat 10 variabel pada data set yang ada . Ada beberapa variabel yang tidak dibutuhkan sehingga harus dihapuskan
langkah 3: Menghilangkan kolom yang tidak diperlukan
Untuk contoh ini, Kides telah menghilangkan beberapa kolom yang tidak diperlukan . Sehingga Kides hanya menyisakan 4 kolom yakni id , id_android,speed dan distance seperti ditunjukkan pada gambar dibawah :
--- Menghilangkan Kolom Yang Tidak Perlu ---
driver = driver.drop(["linha", "car_or_bus","rating_weather", "rating_bus","rating","time"], axis = 1)driver.head()
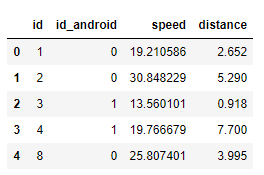
Pada gambar diatas menunjukkan dataset untuk 38092 driver . Selanjutnya menentukan variabel yang diklusterkan , disini Kides menggunakan variabel jarak pada sumbu X dan variabel kecepatan pada sumbu Y .
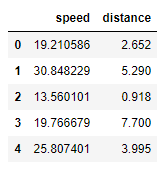
-- Menentukan variabel yang akan di klusterkan ---driver_x = driver.iloc[:, 1:3]driver_x.head()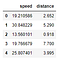
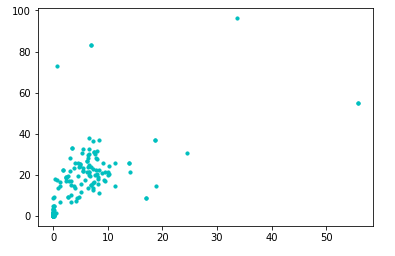
Dataset diatas divisualisasikan persebaran datanya sebagai berikut
--- Memvisualkan persebaran data ---plt.scatter(driver.distance, driver.speed, s =10, c = "c", marker = "o", alpha = 1)plt.show()
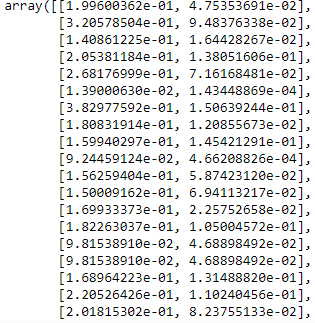
--- Mengubah Variabel Data Frame Menjadi Array ---x_array = np.array(driver_x)print(x_array)

Kemudian Kides harus menstandarkan kembali ukuran variabel . Agar data dapat kembali seperti jenis data diawal sebelum di array kan
--- Menstandarkan Ukuran Variabel ---scaler = MinMaxScaler()x_scaled = scaler.fit_transform(x_array)x_scaled
Tentukan nilai K . Dalam hal tersebut, nilai K (n_clusters) atau nilai arbitrer bebas ditentukan , tergantung kepada peneliti .Pada kasus ini , Kides akan mengkonfigurasi dan menentukan nilai K sebesar 3 cluster. Selain itu Kides juga menetukan kluster dari data yang telah di standarkan .
--- Menentukan dan mengkonfigurasi fungsi kmeans ---kmeans = KMeans(n_clusters = 3, random_state=123)--- Menentukan kluster dari data ---kmeans.fit(x_scaled)


--- Menampilkan pusat cluster ---print(kmeans.cluster_centers_)

Selanjutnya Kides menampilkan hasil cluster dan Menambahkan kolom data frame driver .
--- Menampilkan Hasil Kluster ---print(kmeans.labels_)--- Menambahkan Kolom "kluster" Dalam Data Frame Driver ---driver["kluster"] = kmeans.labels_

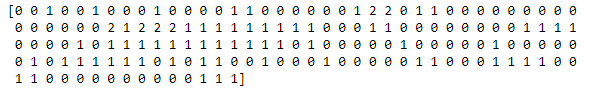
Kemudian memvisualisasikan hasil cluster
--- Memvisualkan hasil kluster ---output = plt.scatter(x_scaled[:,0], x_scaled[:,1], s = 100, c = driver.kluster, marker = "o", alpha = 1, )centers = kmeans.cluster_centers_plt.scatter(centers[:,0], centers[:,1], c='red', s=200, alpha=1 , marker="s");plt.title("Hasil Klustering K-Means")plt.colorbar (output)plt.show()

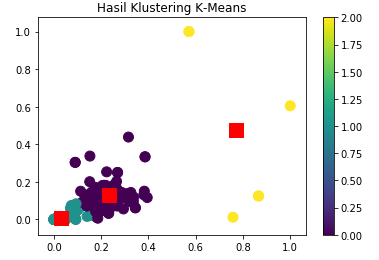
Dari gambar diatas dapat kita lihat bahwa dari data pengemudi Go-Track telah ter cluster menjadi 3 .
K-Means Clustering adalah materi yang mudah dipahami, terutama jika kita langsung mengaplikasikan sebuah data untuk di kelompokka menggunakan K-Means . Dengan c=belatih pada tutorial-tutorial yang ada pasti kita akan cepat paham mengenai materi ini .Namun , kinerja dari K-Means Clustering ini sendiri tidak sekompetitif teknik-teknik pengelompokan canggih lainnya karena sedikit variasi dalam data dapat menyebabkan varians yang tinggi.
Sebenarnya dari algoritma yang kita miliki , kita dapat juga melakukan uji coba untuk mendeteksi data yang kita miliki masuk ke cluster berapa . Namun sangat disayangkan , disini Kides belum menemukan script yang sesuai untuk melakukan uji coba tersebut.
reference:
- pertemuan 11 machine learning Institut Teknologi PLN
- https://medium.com/@16611129/memahami-k-mean-clustering-pada-machine-learning-dengan-phyton-430323d80868
- https://raharja.ac.id/2020/04/19/k-means-clustering/#:~:text=K%2Dmeans%20merupakan%20algoritma%20clustering,yang%20paling%20sederhana%20dan%20populer.



Komentar
Posting Komentar
Silakan tinggalkan komentar jika ini membantumu, sekaligus agar saya semakin termotivasi untuk menulis